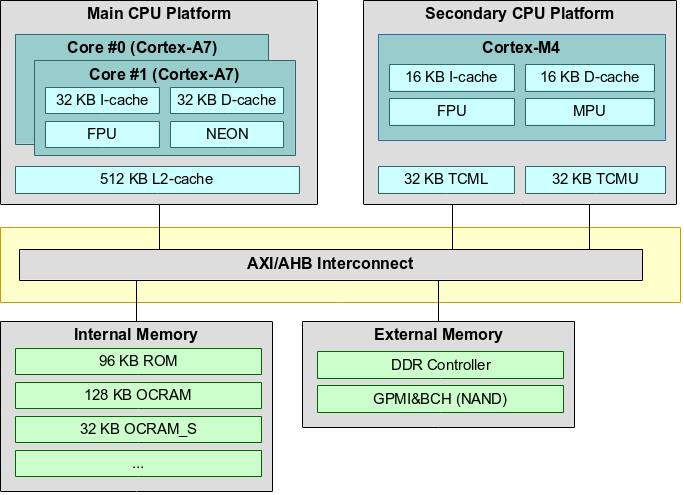
The NXP i.MX 7 SoC heterogeneous architecture provides a secondary CPU platform with a Cortex-M4 core. This core can be used to run a firmware for custom tasks. The SoC has several options where the firmware can be located: There is a small portion of Tightly Coupled Memory (TCM) close to the Cortex-M4 core. A slightly larger amount of On-Chip SRAM (OCRAM) is available inside the SoC too. The Cortex-M4 core is also able to run from external DDR memory (through the MMDC) and QSPI. Furthermore, the Cortex-M4 uses a Modified Harvard Architecture, which has two independent buses and caches for Code (Code Bus) and Data (System Bus). The memory addressing is still unified, but accesses are split between the buses using addresses as discriminator (addresses in the range 0x00000000-0x1fffffff are loaded through the code bus, 0x20000000-0xdfffffff are accessed through the data bus).
I was wondering how the different locations and buses affect performance. I used the Hello World example which comes with the NXP NXP i.MX 7 FreeRTOS BSP (I used the Toradex derivation of the BSP). I added a micro benchmark found and forked on Github and used appropriate linker files memory sections (refer to the i.MX 7 Reference Manual for the list of memory addresses) to load the firmware into different memory areas. I did use rather ancient Linaro 4.9 toolchain (2015q3) Since this is a synthetic and very small benchmark, the numbers are likely not directly applicable to real-world applications!
The standard mode of operation should be fetching data through the system bus and code (.text), unsurprisingly, through the code bus. This provides the best performance (assuming equally good caching on the two buses). Since the system bus is somewhat more versatile, I tested how fetching code through the system bus affects performance. The results are execution time in milliseconds. The micro benchmark was highly reproducible and values never deviate more than 1ms between two runs.
Caches Disabled
| .data | System bus | System bus | Code bus |
|---|---|---|---|
| .text | Code bus | System bus | Code bus |
| DDR | 1329 ms | 1402 ms | 1357 ms |
| OCRAM | 401 ms | 486 ms | |
| OCRAM_EPD | 564 ms | 604 ms | |
| OCRAM_S | 840 ms | 910 ms | 861 ms |
| TCM | 45 ms | 72 ms |
System Bus Cache Enabled
| .data | System bus | System bus |
|---|---|---|
| .text | Code bus | System bus |
| DDR | 1290 ms | 72 ms |
| DDR (non-cached area) | 1438 ms | 1486 ms |
| OCRAM | 387 ms | 72 ms |
| OCRAM_S | 812 ms | 93 ms |
System and Code Bus Cache Enabled
| .data | System bus | System bus |
|---|---|---|
| .text | Code bus | System bus |
| DDR | 1406 ms | 72 ms |
| DDR (non-cached area) | 1437 ms | 1486 ms |
| OCRAM | 540 ms | 72 ms |
| OCRAM_S | 66 ms | 93 ms |
Observations
- Unsurprisingly TCM is the fastest memory. There seem to be a difference in access times between OCRAM areas.
- The DDR memory area which can be cached is limited to the first two megabyte according to the i.MX 7 Reference Manual (see note in chapter 4.2.9.3.5 Cache Function,
0x80000000-0x801fffff). However, in tests it seems that the first four megabytes are cacheable (0x80000000-0x803fffff). Everything after0x80400000seems to be definitely uncached (row DDR non-cached in the results) - Fetching Code through a cached System Bus is much faster than fetching code through an uncached Code Bus.
- It seems that Code Bus Cache does not work for DDR and OCRAM, which is somewhat unfortunate. The above mentioned chapter even suggests that caches cannot be used for any code bus memory region (??).
- The test was run using the default MPU cache settings. Changing the MPU cache bits had no impact in most measurements…
Note that when running from TCM caches do not affect performance, since the Cortex-M4 already has access to TCM with zero wait-states. In fact, the Cortex-M4 block diagram in the i.MX 7 Reference Manual suggests that access to the TCM does not even reach the cache controller. Verification measurements also showed that running a firmware from TCM with caches enabled were exactly the same as without cached.
Firmware from DDR memory whiel running Linux
The cacheable DDR region is located rather unfortunate when running Linux on the primary cores: The Linux kernel program code by default gets unpacked to 0x80008000, and is not relocated subsequently, hence the area is occupied by the Kernel. It is possible to move the text base by adjusting textofs-y in arch/arm/Makefile. Setting it to 0x00208000 puts the kernel one megabyte into DDR memory (see .text section):
[ 0.000000] Virtual kernel memory layout: [ 0.000000] vector : 0xffff0000 - 0xffff1000 ( 4 kB) [ 0.000000] fixmap : 0xffc00000 - 0xfff00000 (3072 kB) [ 0.000000] vmalloc : 0xa0800000 - 0xff000000 (1512 MB) [ 0.000000] lowmem : 0x80000000 - 0xa0000000 ( 512 MB) [ 0.000000] modules : 0x7f000000 - 0x80000000 ( 16 MB) [ 0.000000] .text : 0x80208000 - 0x80a7d820 (8663 kB) [ 0.000000] .init : 0x80a7e000 - 0x80ace000 ( 320 kB) [ 0.000000] .data : 0x80ace000 - 0x80b164c0 ( 290 kB) [ 0.000000] .bss : 0x80b19000 - 0x80b7838c ( 381 kB)
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
cortexm4@80000000 {
reg = <0x80000000 0x200000>;
};
};
In another test I tried to make use of the area using the continuous memory allocator (CMA). I had to set FORCE_MAX_ZONEORDER in arch/arm/Kconfig to 10 to allow CMA allocations of just two megabytes. I then could reserve the area for the CMA allocator using this device tree entry:
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x200000>;
linux,cma-default;
alloc-ranges = <0x80000000 0x200000>;
};
Hi, nice post. I found your other blog a couple of days ago searching for ways to boot Linux on a Vybrid CPU. I’ve trying to compile everything with upstream code(u-boot,linux,rootfs(using buildroot)). the bootloader is running successfully on the board, but after loading the compiled kernel and rootfs on the microSD, it does not load it. I see that you have experience with this processor. could you maybe take a min of your time. My current progress is here http://new.cafferata.me/myembeddedworkshop/?p=79 . Thanks
“Starting kernel …” is the last message printed by U-Boot. It looks like Linux is crashing during unpacking or very early boot. Maybe it is overwriting the device tree which is rather low at 0x81000000. Try adjusting variables (e.g. move device tree from 0x81000000 higher up e.g. to 0x84000000). Otherwise, try using CONFIG_EARLY_PRINTK for Vybrid (under Kernel Hacking) and pass the earlyprintk parameter. With that you should see more than “Starting kernel …”.
May be it’s helpful to note the silicon revision (si_rev, can check when U-boot boots) of the SoC tested, as per NXP forums older silicon (<=1.0 ?) had non-working /broken cache.